Twitter scraper tutorial with Python: Requests, BeautifulSoup, and Selenium - Part 1
Published: 2016-03-26
Inspired by Bruce, my friend’s take-home interview question, I started this bite-size project to play around with some of the most popular PyPI packages: Requests, BeautifulSoup, and Selenium. In this tutorial, I’ll show you the step-by-step process of how I build a Twitter Search web scraper without using their REST API.
“Well, why not use their API?” you might ask. I have two reasons:
Not all the websites expose REST APIs to clients. In order to retrieve data from those websites in a programmatic way, it’s good to know how to do web scrapping.
To use Twitter’s APIs, you’ll need OAuth to authenticate your application. I was just too lazy to figure that out at the time. (Yeah, I’ll figure it out and post another tutorial on that.)
Here we go! Fire up your favorite browser and go to the url: https://twitter.com/search-home. You’ll see a text box in the middle. That’s where we begin. Try typing in something that you want to search and see what happens. For me, I want to search for all tweets from my twitter account, @dawranliou. So I typed it in and hit enter.
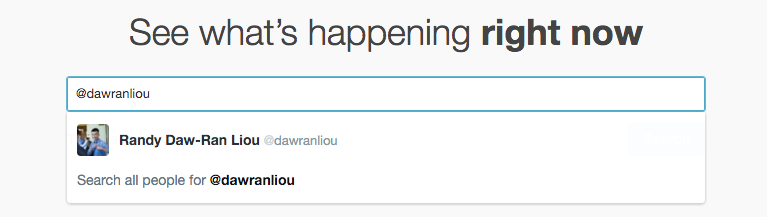
In the next page, you can see a list of tweets. Let’s make our first note here: what’s the current url? For my search results, it is https://twitter.com/search?q=%40dawranliou. This url is important since the python application we are writing will need it to retrieve the same data we are viewing on the browser now.
Second, open your developer tool. For me, I use Chrome browser on my Mac so I hit “command-alt-I”. Here’s where a little bit detective in you and me need to come into play. What we are looking for is some hints indicating the tweets that we see on the browser. Later on we could use those hints in the code to find the information we need in a programmatic way. Let’s take a look…
tag and it has the class attributes of “TweetTextSize”, “js-tweet-text”, and “tweet-text.”
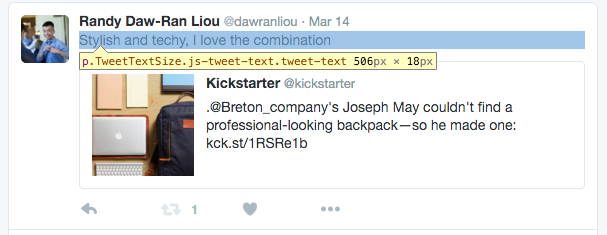
tag and the same class attributes. You can verify it by inspect more tweets. Bingo, this is what we need. Let’s get down to the code:
import requests
from bs4 import BeautifulSoup
url = u'https://twitter.com/search"q='
query = u'%40dawranliou'
r = requests.get(url+query)
soup = BeautifulSoup(r.text, 'html.parser')
tweets = [p.textfor p in soup.findAll('p', class_='tweet-text')]
print(tweets)Boom! Easy huh? Two packages I use are: 1. Requests: it makes sending HTTP requests super easy 1. BeautifulSoup: it makes parsing html super easy. And I love the name :)
The code is very self-explainatory. Let’s run it!
python3 twitter-search.py
[]What… why? Empty list? That doesn’t make sense. Let’s not panic. Keep calm and open the python interactive mode to see what’s going on in the code.
python3 -i twitter-search.py
[]
>>> f = open('search.html', 'w')
>>> f.write(r.text)
97075Here I output the response to our HTTP request to a file. Locate the file and open it up with your browser.
I do not see the tweets this time. So what’s happening here is that the web application design is very sophisticated that the tweet search results aren’t loaded, YET, when the HTTP response is back from the server. Instead, those tweets were loaded asynchronously using AJAX (stands for Asynchronous JavaScript and XML) calls. With this design, the website could be loaded up very light-weighted at the beginning. As the user scrolls down the page, more contents will be loaded without the need of refreshing the page. This design is called Infinite Scrolling.
In part 2, I’ll show you how to use Selenium, another very popular PyPI package, to scrape the infinite scrolling page. Stay tuned!